Typically you and your company will be at a breaking point. They want more features and you as a developer are trying to keep your head above water just on maintenance for the old stuff. For example a new security issue like this one we had http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2013-2251 could crop up and it is forcing an upgrade. But can you? Are you assured that you can make this upgrade and not break anything? You could make the change and re-test the entire system manually, but how long will that take? Can you get it done before some gains complete control of you server? Do you even know how to test the entire system? Are you agile enough to get this done fast? If the answer is no then it is time to make some changes.
The DevOps side of you is saying you need automation. You need to be able to make a change and get that single change out the door and into production quickly. But how do you get there? Unfortunately there is not a single thing to do or change that is going to make this happen. In our case study, everything needed to be changed.
Lets start with a goal. I made a goal for the system. I wanted to have a single change come in from the business or myself and have it pushed out into production in under a week. I decided we needed to cut development cycles down to 1-week sprints. Before I got there the company was used to 4-6 month projects. This was a hard culture change to get through to people.
One of first things the CEO wanted to do when I came onboard was to plan out the next year. Instead I persuaded him to just focus on the current priority now. Because no matter how well we do, whatever we think we should do 6 months to a year from now typically won’t be at the top of the priority list anymore. Basically I was saying to him. Lets be Agile.
We needed to change the project so that our project could handle change. We needed the whole process to be greater than the sum of its parts. I knew that if we were firing on all cylinders, and if all of tools were integrated and automated, and we had a highly sophisticated continuous integration pipeline, then productively would rise and we would be in a lot better shape. This is the basic goal of DevOps.
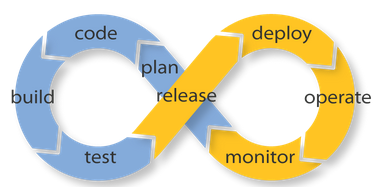
What is DevOps
I get a lot of recruiters contacting me, claiming that they have an Urgent need for a DevOps person. Unfortunately the job description usually says otherwise. Typically they want a System Administrator. The Wikipedia Definition of DevOps is:
DevOps is a software development method that emphasizes communication, collaboration (information sharing and web service usage), integration, automation, and measurement of cooperation between software developers and other IT professionals.
I think the most important part of this definition is that DevOps is a “Software Development Method.” It is not just a buzzword. It is a Software Development methodology not a System Administration methodology. It is going to take some sys admin skills, however.
Making changes in Baby Steps
First thing on my plate was to setup some tools. I brought in an old Dell workstation from home; put it on my desk and setup VM Ware workstation on it. I needed some virtual machines to run the tools required to kickoff this process. I bought with my own money a starter license of Atlasssian Jira and Greenhopper. I did not want money to be a barrier to upper management. It would be easier to show why we needed to do this, than explain. But more importantly, I need these tools in place ASAP. I wanted the project manager to start writing stories and capturing them in more public way, immediately. Before she was using Microsoft Word and Project. It was a little bit of a fight, but after she started to research Scrum and Agile she was willing to give it a try.
For myself, I was in a bad spot. My number one priority was to figure out how they built the code and to be able to build it myself. I focused on the projects that were done from the command line, opposed to the projects build in the IDE. I also had a version issue. I wasn’t exactly sure which version of the code was running in production. There were tagged CVS trees and code that was being built in the IDEs that were slightly different. I decided to go with the latest CVS version and release that ASAP to see if anyone noticed anything missing so that I could have my baseline.
Once the baseline was determined I set out to reorganize everything into Maven builds. Once I have Maven builds for everything. I setup a Git Repo checked in everything and setup a basic continuous build system with Jenkins. At this point the code building process was truly platform independent. It did not matter anymore that I was using Intellij as an IDE apposed to Eclipse. Maven was the only dependent factor. I could basically walkup to any box with maven and git installed and do a:
git clone <a href="http://myrepo">http://myrepo </a>cd project mvn clean compile war
I would then have a war file to deploy. I deployed those and now I had my new baseline to work from.
Pieces are starting to fall into place
Now that I had a proper list of dependencies defined into my maven pom files. I was able to strategically dissect the application. I needed to find the low hanging fruit and I also needed to get to the point of what I call push button deployments. Where I could push a button in the build system and deploy code into production. I needed a way to make it less painful to do a release, because I would be doing a lot of them and doing them frequently. That’s a big part of releasing often. If the release process is absolutely painless it becomes simple to do. But first I needed some architecture changes on the database front.
It is a bad idea to do a cluster over a WAN link. A cluster over a shaky OpenVPN connection is even a worse of an idea. That type of VPN is really for road warrior type of users/clients and not network-to-network connections. Our databases would get out of sync often. So I broke up the cluster and had the remote app in South America connect to the database over the VPN connection. It was not perfect, but was a start to buy us some time. Eventually I planned a re-write that application to make web service calls instead and not have a database at all.
Enter the Cloud
I needed the cloud. There was no way I could also be system administrator to physical production hardware and also do this amount of development. Also given our physical server locations, it made it impractical to maintain, and it was just plain expensive. In my opinion there is only one public cloud choice. That would be Amazon AWS. Nobody can beat Amazon’s virtual network services. For example they have routers to create virtual private networks and load balancers that can host SSL certificates. And the price was cheaper than hosting at our sub-leased space at the co-lo.
Persuading the powers to be was difficult. I’m not sure why. I’m not sure if some FUD (Fear, Uncertainly, and Doubt) was being passed around the non-technical circles. But there was a lot of push back from people who were concerned that our data was going to be out there for everyone to see and have access. I partially blame consumer grade services like dropbox that were advertising “store your data into the cloud”. Things like that diluted the meaning of the “Cloud” and my management team thought that was what we were going to be doing. It was a hard for me to convince them that what we were actually doing was renting a slice of a server. I need a test case. I didn’t have to go too far to find one. Our junky FTP/SFTP server.
The FTP server I inherited was in bad shape. SFTP access wasn’t locked down. So if you had a SFTP account, it meant you really had a full SSH account into the box as well. Since this was on our production network, this had to go. Using a free for a year Amazon AWS linux instance in a completely isolated network, I setup a new server with only SFTP access. This provided enough evidence needed to show management that this can be done and its better than our current setup and it was cheaper as well.
After I got approval to move into the AWS cloud I started to migrate my apps over. I upgraded the Operating Systems but had to leave the JBoss application servers alone. The application required JBoss service archives and the JBoss server could not be upgraded to the latest version as the JBoss team decided to drop support for service archives in newer versions.
Think of Service archives as java programs that runs in the background and in my case they were doing batch like tasks. This was my first opportunity to do some major java refactoring. I decided to redo each SAR (Service Archive) as a Spring Batch Job and run it in a new up-to-date Tomcat Server. Once I was able to decouple all of the SARs out of my deployments I was then able to redeploy the main applications onto Glassfish Application servers. This sounds easy, but it actuality took a lot of time to get there. This new “Batch Server” as I called it was following all of the current best practices. Including unit and integration test automation, one click deployments, and all into the AWS Cloud.
With my base architecture and infrastructure in place, it was just a matter of time before I could say I reached my goal. Weekly I would release new code, adding more tests, and removing old things, at the same time adding new features to the system as they were requested.
In the next part I will go over my Test and Development environment. This is really the heart of it all. From the DevOps perspective this is where the magic happens.