Lately my desktop operating system has been letting me down. I’m an Enterprise Java developer and my computer is what puts food on the table. For the past 10 years my weapon of choice has been MacOS on MacBook Pros. I typically buy these myself as a “company box” usually won’t cut it.
The Mac platform has been working great for a long time. But things started to go down hill when in 2010 Steve Jobs announced no more Java from Apple. Apple Insider – Apple deprecates Java
From Apple JDK Release Notes circa Oct 2010.
Java Deprecation
As of the release of Java for OS X v10.6 Update 3, the Java runtime ported by Apple and that ships with OS X is deprecated. Developers should not rely on the Apple-supplied Java runtime being present in future versions of OS X.
The Java runtime shipping in OS X v10.6 Snow Leopard, and OS X v10.5 Leopard, will continue to be supported and maintained through the standard support cycles of those products.
I should have stop buying them right then and there. Apple just kicked all of the Java developers off of their platform. Around the office we talked about what we would do. OpenJDK was kinda of an option, but not really as it wasn’t ported to Mac. At the time, the real Apple JDK was still the best platform for Java development. Luckily after a while in limbo, Oracle announced that they would be creating an official JDK for the Mac platform. That promise kept me on the Mac.
New computer time
Fast forward to 2015 and it is time for a new computer. My workload is little bit more intensive than it used to be. Apple doesn’t really seem to support what I do. To make matters worse Apple products are not that changeable/upgradable. My 2012 Macbook Pro is completely non upgradable. The RAM is soldered on and the SSD has a proprietary connector, even though it didn’t need to be. They could have used a standard M.2 SSD. They literally just moved some pins around so that you couldn’t buy one off the shelf.
The Linux challenge is about me finding out if the grass is greener on the other side. Apple tends to cater to 2 demographics. I will call them General Purpose Users (AKA – Web Surfers/Youtube watchers) and content creators. Content creators are people that are creating and editing digital media, like post production editing of photos and video. However – the content creators are not too happy with Apple either.
There’s a common misconception that Apple hardware is over priced. It is not. When you compare Apples to Apples 😉 . You will find the prices of the hardware (when it 1st comes out) is actually pretty good. They just don’t ever use low end hardware. So you while it is true that you can go to the store and buy a $300 windows laptop. The specs won’t match up to the Apple laptop that costs 3 times as much.
The Real Problem with Apple Hardware
High-end predetermined specs leads to a problem though. Most people would probably think the Mac Pro workstation would be a good choice for a guy like me, but I am not going to pay a premium for that extra workstation grade graphics card and you cannot get around it. I have a $200 desktop grade graphics card in my Hackintosh and it can drive 2 4k monitors just fine. I’m not rendering video so why should have to pay for it? The base model config is probably adding about $1000 to the price of the box (or trash can if you prefer). I rather spend that money on more cores or more memory. Thunderbolt didn’t exactly take off, leaving your only external I/O solution as something that seems to be teetering on a cliff. I find it odd that even apple doesn’t have a external disk solution.
Stop asking for a handout
I feel like my Operating System is begging for money. The App Store, iCloud, iTunes, Beats Music, even the new Photo app wants my credit card info so they can sell me things. I just want to get my work done. I don’t need the constant upsell pitch.
I don’t really like those apps anyway. I really don’t like the new Photos App. I’ve been putting off upgrading my machine that has my main iPhotos Library. I don’t like how I need iCloud to have photos from my phone, sync with my desktop library. Well, let me clarify. I want them to sync. But they made it so that it has to store the photo in iCloud and if you go over 5gig of storage you pay per year. I don’t take alot of photos. But – I’ve been doing digital photos for over 15 years. my Pictures folder (which includes iPhoto) is 25 Gig. I would have to get their 200GB plan at $3.99 a month. And this is for something I don’t need or want. I don’t need to actually store my library in the “Cloud”. I just need the damn thing to sync (my Phone to my Desktop).
Yosemite is Apple’s Windows 8
Yosemite has been very flaky. Its hands down the most problematic release they ever did. But what put me over the edge was Java. AKA the bread and butter – the money maker. Unfortunately I’m having issues with Mac version of the Java JDK from Oracle. Things were ok when I was using version 6 – the last version from Apple, I resisted upgrading as long as I could but, all my tools started requiring java 7. I can honestly say that the Oracle version is just not as good as the Apple version. And I probably wouldn’t expect it to be.
Who is in a better position to make it work the best? Apple or Oracle? All someone has to do at Apple on the Java team that needs something done or needs some insight on something low-level in MacOS is go find someone from that team in the cafeteria. When Apple was in control of Java on the Mac platform it was truly a first class citizen. Not so much now.
The Good things
So that’s alot of hate. What do I like. I like the messages app and I like time machine. I require a Unix command line interface. Mac’s terminal app is really the best in the business in its stock form. Cut and Paste in works great. Most things just work, with very little hassle. The UI allows me to be very productive. It gets out of my way. Everything is integrated together out of box with very little custom configuration for anything. Most importantly everything is consistent. Let me give you an example that drives me batty.
Every single linux distro I’ve used in the past 2 years has in the desktop environment has ctrl-c as copy and ctrl-v as paste. Pretty normal stuff. And it typically just works except in one place. The terminal. The terminal has those mapped to shift-control-c and shift-control-v. There is a technical reason why, however I can also come up with a decent work around in code to fix it (If there is a program running in the foreground send it ctrl-c else if I’m at the prompt do a paste). I truly believe it is because not everyone is working together. The terminal guys don’t have to look the Desktop environment guys in the eye in the lunch line and explain why they can’t do this simple fix and thus have a consistent feel.
Windows 8.1/10 not an option
When Java 6 went to EOL status in Feb of 2013, I started looking. Windows 8 was a complete clown show. I bought my 5 year old son a $300 ASUS touchscreen laptop. The touch screen is good for a 5 year old, but the computer was a nightmare. I don’t think they actually tested the parental controls. If you had it turn on, booting the machine would give errors about how software couldn’t be updated because of permissions. The App store begged even hard for money than the Apple version. trying to add a network printer also got the thing tossed out of window. There were so many steps just to shut it off, I thought several times that it be quicker just to smash it against the wall. Needless to say, this was not going to be an Operating System to put food on the table. That really just left Linux
Linux looks good from a distance but….
On paper Linux looks like the clear winner over everything else. But not so fast, Linux on the desktop suffers from an unlikely source, the Open Source zealots.
I’m not an Open Source zealot. My computer is a very important tool to me. I don’t care If I can see the source code or if it free. I needs it to be, powerful, advanced, and it needs to just work. I need to have the best tool for the job. I watch a lot of tech shows on YouTube and follow tech podcasts. I’m particularly fond of Jupiter Broadcasting and their Linux Action Show. These guys are hard core open source advocates and its interesting to see and hear them and their community, especially when it comes to switching people over to Linux. I was pretty excited when they announced that the host’s wife was going to be switched from her MacBook Pro to Linux and they were going to document the process. I think that has inspired me to give it another shot as she didn’t immediately give up on it. As far as we know.
I must say, I don’t quite understand where all of the passion for open source comes from. I’m a software developer, open source kinda competes with me. These shows/podcasts are mainly put on by IT people. I’m willing to bet that they don’t think their services should be free. Why should mine? That being said, I try to find a free and open solution to any problem I’m trying to solve. My main reason is that I don’t want to be locked in. Open is good for not being locked in. Look at what happened to MySQL. People didn’t like where Oracle was going so they forked it. Or look at Hudson. People didn’t like where Oracle was going with it, so they forked it. Maybe the evil empire is really Oracle and not Microsoft!
My point is, Free or Paid. I don’t care. I just need it to work. Don’t go switching to Linux just because its free and open. Switch because it works better for your particular workload better than anything else out there. Time is money. If a $120 license of Windows is going to work better for you and your job, I would say that’s money well spent.
Full disclosure. I do consider myself an Linux expert (but not that much of an advocate). I first loaded a PC with Linux around 1993. I did it because I was into computers, halfway through my Computer Science degree, and I wanted what the professors was using. Well, I can’t say it went well. Hardware support was very lacking and the system just didn’t work good at all. I ended up buying a used Sun Workstation IPC off of USENET. I used that for the rest of my college years. Every 6 months or so I would go an try it again with the latest Slackware CD included some random magazine, typically with the same results.
In 1996 my first Job out of college, I had a Sun workstation for my office computer and I was working on embedded C projects. This is when I took my first real Linux challenge. Something amazing happened around that time that triggered it. KDE. KDE came out and it was such a nicer desktop environment than Solaris/CDE that I had to try it. It was still in beta at this stage but It worked for my project and overall it was a pleasant experience, hard as hell to get running, because in those days you had to compile everything yourself.
One of the nice things about have a Linux workstation at that time as a C developer, was having the GNU C compiler. And having it for free. Back in the day, we would have to pay a hefty sum to get the Sun C Compiler. And I mean hefty!!! I don’t remember the price, but I do recall several thousands of dollars.
I started professionally writing Java code in 1998 on Sun workstations, but transitioned to Linux Workstations around 2001. Then to Macs around 2004. That was a painful 3 years with Linux on the desktop. However Linux on the backend has been life changing. Also around 2001, I started moving my projects to Linux servers from Sun servers. In 2011 I retired the last Sun Server I ever used. That server was our production Oracle Database. We transition to Linux and high end commodity X86 based servers for about a 10x performance boost. I’m also a Certified Red Hat System administrator. So I’m not exactly a newbie. I truly just want the best desktop I can have, and Linux on the desktop was hard in the past. But I am willing to give it another shot.
If the community would have stayed the course, you probably would not be reading this
Linux could have won the desktop wars with KDE and there wouldn’t need to be any challenges to do. But the Open Source zealots wouldn’t have it. KDE was built on a library called QT. And QT wasn’t open source. It was free to use, but it didn’t have a proper open source license. So GNOME was born, effectively splitting the developement base between 2 competing projects. This happens a lot in the open source Linux world. And keeps Linux dragging behind competing platforms like Windows and MacOS on the desktop. It is actually pretty damn annoying. KDE and Gnome apps can run side by side, however they use different widget toolkits making the look and feel different between apps. This is a distraction to me and it hurts my productivity (I know it sounds like whining). I know it is a little strange, but is too much to ask for all of apps to kinda look the same?
The Linux Challenge for 2015 involves evaluating the Linux desktop to see if the distractions have gone away and to see if I can at least be as productive on it versus my Mac which I consider a little bit broken with Yosemite. Early testing says yes.
Where am I going to test
Back when I was considering just sticking with Apple I ran into a hardware problem that I explained above. This lack of hardware choices forced me to build a Hackintosh. Specs here:
Hackintosh – PC Part Picker list
I wanted a new box but wasn’t convinced that I needed a laptop anymore. Everything is so cloud and web based that you can practically use anything thing with a web browser and get your work done, BTW what happen to the Sun Ray thin clients that you could “Hot” desk with a smart card? Basically you would walk up to any desktop client stick your smart card in and resume your desktop session. this was the best idea EVER in desktop computing.
So I built a Hackintosh that I call “Artic Panzer”. I’m getting Mac Pro performance, for about $1000 cheaper mainly because of the video card (singular). It works great. No complaints. However, I’m having the same issue with it that I’m having with my laptop. The IDE I’m using (Intellij) has problems editing JSP pages with javascript embedded. Its causing performance hiccups (delays). Its not so bad on the 6 core workstation, but it is still there.
I have been testing Linux desktop distros for 2 years on a dedicated laptop. So this was something I could quickly isolate to Java on MacOS. I tried Intellij with the same code on a way slower laptop and found no performance hiccups at all. So the problem is Intellij on Mac with the Oracle JDK on mac. This is the straw the broke the camel’s back. Its time for the 2015 Linux Challenge.
Current Plan
Phase 1:
Test out all of the applications I need on my Samsung Series 5 Laptop.
Specs:
- 15.6 1366×768 Display
- 3rd Gen Core i7-3537U (Geekbench 2666/5455) 2 Core/4 threads
- 16GB RAM
- SSD (Various models – depends on what I’m testing)
- Arch Linux on Samsung 850 SSD
The goal is to find a configuration that works and
Phase 2:
Rebuild with Final App Config.
Phase 3:
Switch Hackintosh to Linux based on Final Laptop config. Performance test. Am I really gaing anything by going big? Or will a modern laptop do the trick?
Phase 4:
Decide on work configuration. Might wait for 5th gen or 6th gen Intel high-end (Non “U” SKU) laptop processors. 5th gens are trickling out now. 6th gen seems to be closely following. Might pay to wait a little. I would love to use my samsung laptop but it can only drive a 1080p monitor and I’m a lot more productive on something that is at least 2560×1440.
In these next part I will go over in detail my workload and the apps I need to run and how I accomplish this on the Linux platform.



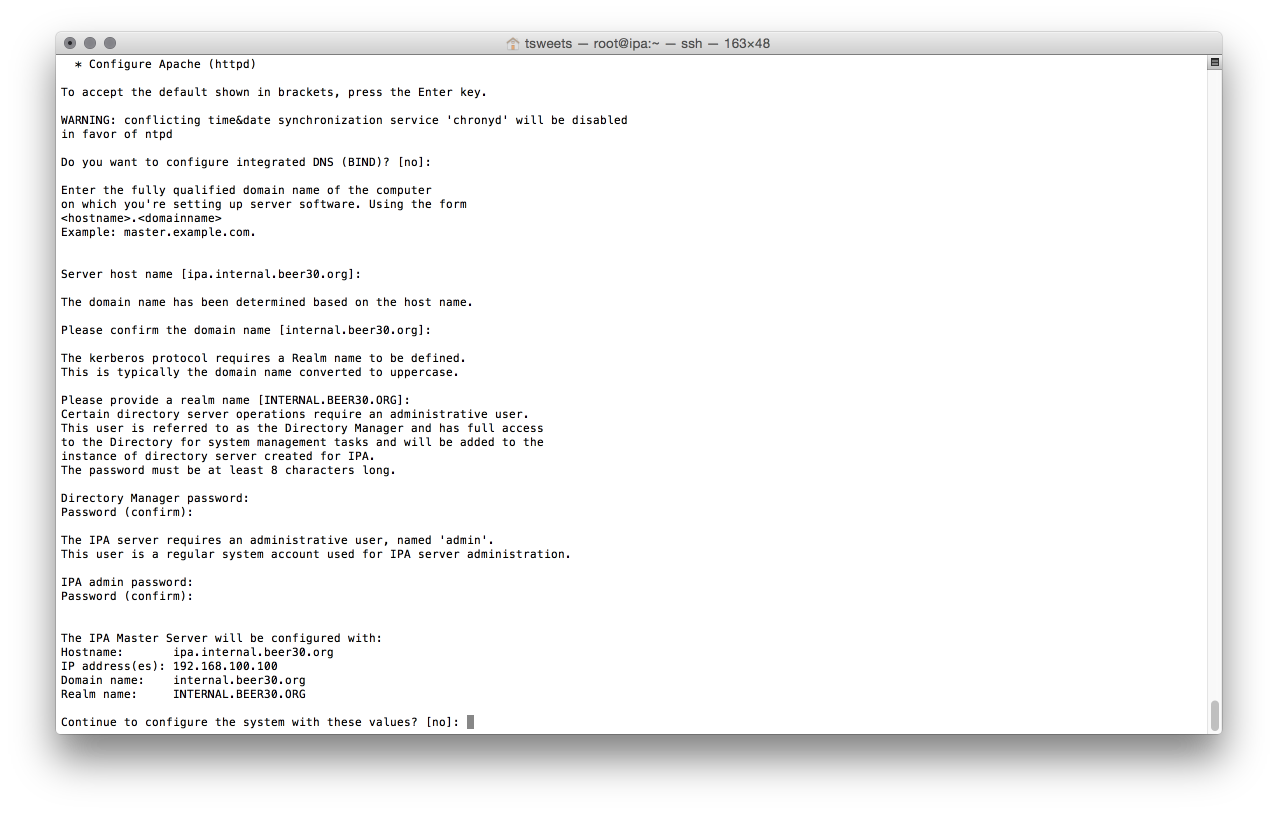
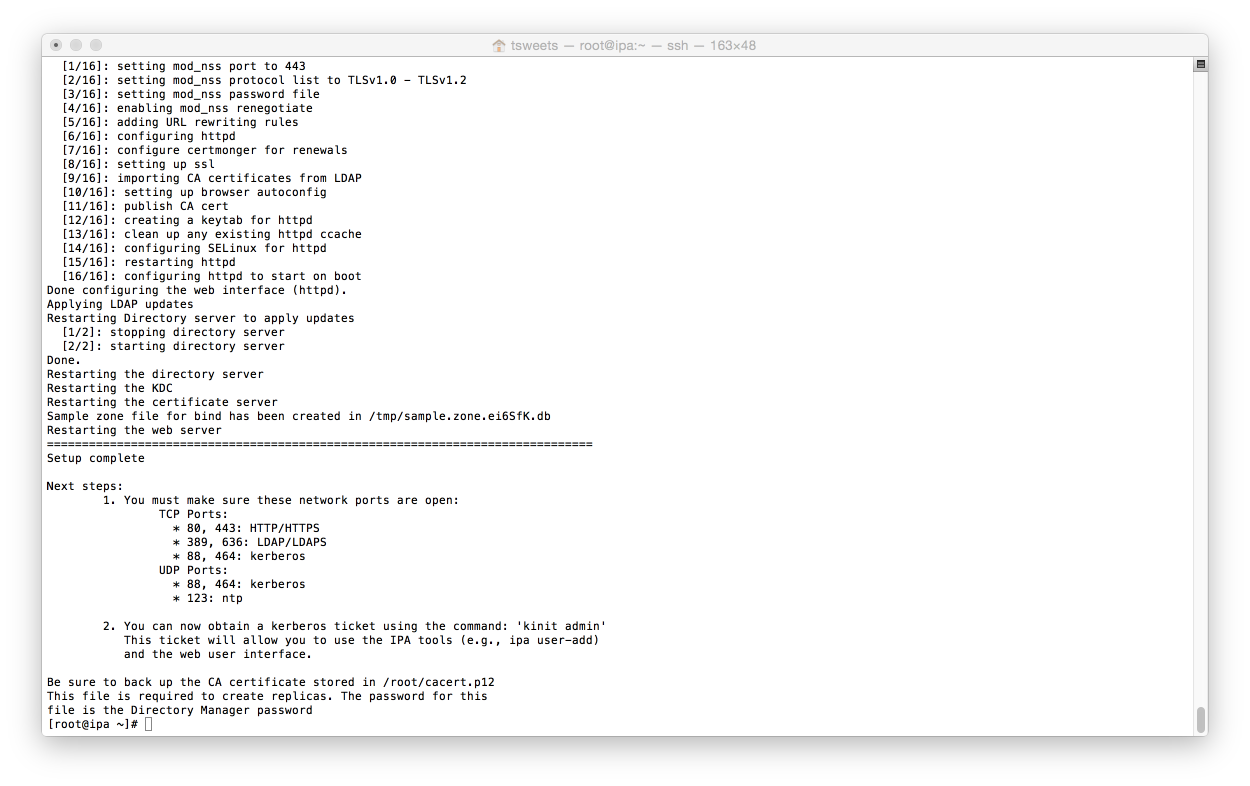
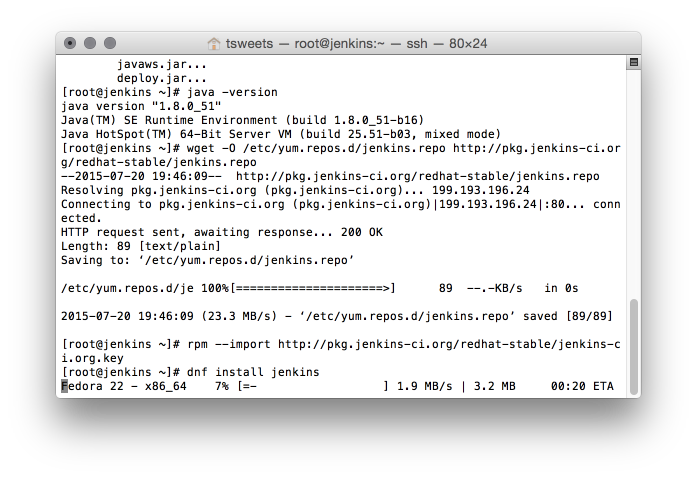
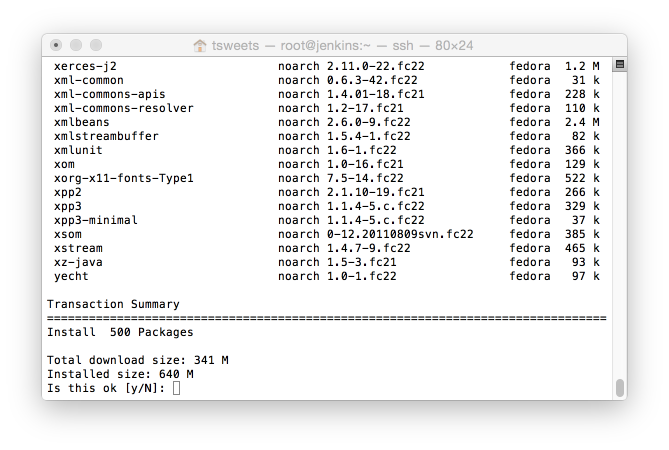
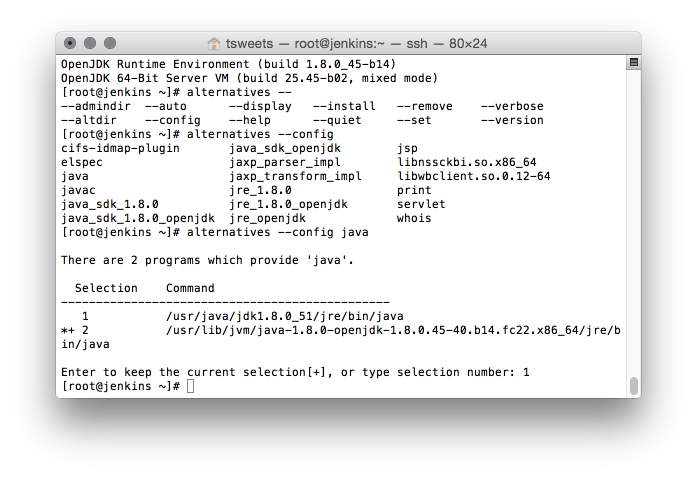
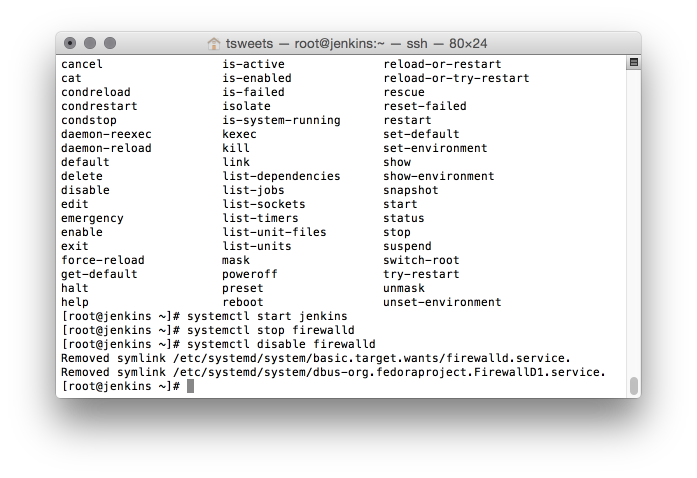
![Dashboard [Jenkins] 2015-07-20 20-55-16](http://www.beer30.org/wp-content/uploads/2015/07/Dashboard-Jenkins-2015-07-20-20-55-16.png)
![Configure Global Security [Jenkins] 2015-07-20 20-56-51](http://www.beer30.org/wp-content/uploads/2015/07/Configure-Global-Security-Jenkins-2015-07-20-20-56-51.png)
![Configure Global Security [Jenkins] 2015-07-20 20-58-31](http://www.beer30.org/wp-content/uploads/2015/07/Configure-Global-Security-Jenkins-2015-07-20-20-58-31.png)
![Dashboard [Jenkins] 2015-07-20 20-58-55](http://www.beer30.org/wp-content/uploads/2015/07/Dashboard-Jenkins-2015-07-20-20-58-55.png)
![Dashboard [Jenkins] 2015-07-20 20-58-07](http://www.beer30.org/wp-content/uploads/2015/07/Dashboard-Jenkins-2015-07-20-20-58-07.png)
![System Information [Jenkins] 2015-07-20 21-06-49](http://www.beer30.org/wp-content/uploads/2015/07/System-Information-Jenkins-2015-07-20-21-06-49.png)